




Data science has rapidly emerged as a central field in technology, research, and industry. At the Texas A&M Institute of Data Science (TAMIDS), our mission is to advance data-driven discovery across disciplines by promoting research, education, and collaboration in data science.
The Multifaceted Nature of Data Science
Data Science is the study of data to extract meaningful insights that inform decision-making. It employs a multifaceted approach, integrating methods from mathematics, computer engineering, machine learning, and artificial intelligence to analyze large datasets.

As a Science
While empirical science has long utilized data (e.g., Kepler’s use of astronomical data), data science views data itself as a valuable resource and focuses on developing methods to extract insights, predictions, and useful narratives from it. It is not a science of data in the sense of researching data’s properties, but rather a scientific way to use data to inform reality.
As a Research Paradigm
Data science is considered the fourth paradigm of scientific discovery, following the empirical, theoretical, and computational paradigms. The “data exploration” paradigm involves capturing or simulating data and then analyzing it to infer new scientific knowledge, often without a preconceived hypothesis.


As a Research Method
Integrating tools and methods from mathematics, computer science, machine learning, and artificial intelligence, data science takes an interdisciplinary approach to conducting research. The application of machine learning and AI to large, complex datasets can transform research from a deductive to an inductive process.
As a Discipline
Data science is fundamentally an interdisciplinary field at the intersection of mathematics, domain expertise, and computer science. The term “data scientist” became prominent because it helped recruiters specify the type of employee they were seeking for data-driven projects—professionals with the training and curiosity to make discoveries from data.
- Statistics and Probability: inference, uncertainty quantification, experimental design, hypothesis testing.
- Machine Learning: algorithms that learn patterns for prediction, classification, clustering, recommendation, anomaly detection, NLP, computer vision, and time series.
- Programming and Software: data wrangling, reproducible pipelines, APIs, deployment (often in Python or R, with SQL for data access).
- Data Engineering Foundations: acquiring, cleaning, transforming, and storing large or complex datasets reliably.
- Visualization and Communication: exploratory analysis, dashboards, reports, storytelling for stakeholders.
- Domain Knowledge: framing the right questions, interpreting results, and aligning with business or scientific goals.

Beyond the Data: How We Got to the Science
Since Thomas H. Davenport and DJ Patil described data scientists as the “sexiest job of the 21st century” in 2012, the discipline has continued to grow in importance across all sectors. University programs, including those established at TAMIDS, aim to equip students and professionals with essential skills—such as Python, R, and machine learning techniques—but the foundation of data science extends far deeper than any particular toolset.
Not Just a Modern Trend, Data Management is an Ancient Practice.
The core of data science is rooted in humanity’s longstanding quest to understand and manage the world through the use of data. Historical artifacts, such as the Ishango bone and clay tablets from Mesopotamia, demonstrate that structured data collection and analysis have been vital for millennia, far predating modern computational technology. Ancient records, from Egyptian censuses to the complaint tablet of Ea-nāṣir and early commercial ledgers, highlight that the fundamental drive of data science is timeless.
While data science’s functional roots are closely linked to statistics, often referred to as the “grammar of data science,” it has evolved into an independent, strategic domain that can complement or replace traditional statistical roles within organizations.
Good Science is Data Preparation.
While the public sees data scientists developing complex models and analyses, the data preparation accounts for approximately 80 percent of a data scientist’s workflow. Data science is often an iterative process or workflow involving “all aspects of gathering, cleaning, organizing, analyzing, interpreting, and visualizing the facts represented by the raw data.” Often referred to as the Data Life Cycle, the main steps include:
- Data Collection
- Cleaning the Data
- Processing and Organizing
- Data Analysis and Interpretation
- Sharing and Visualization
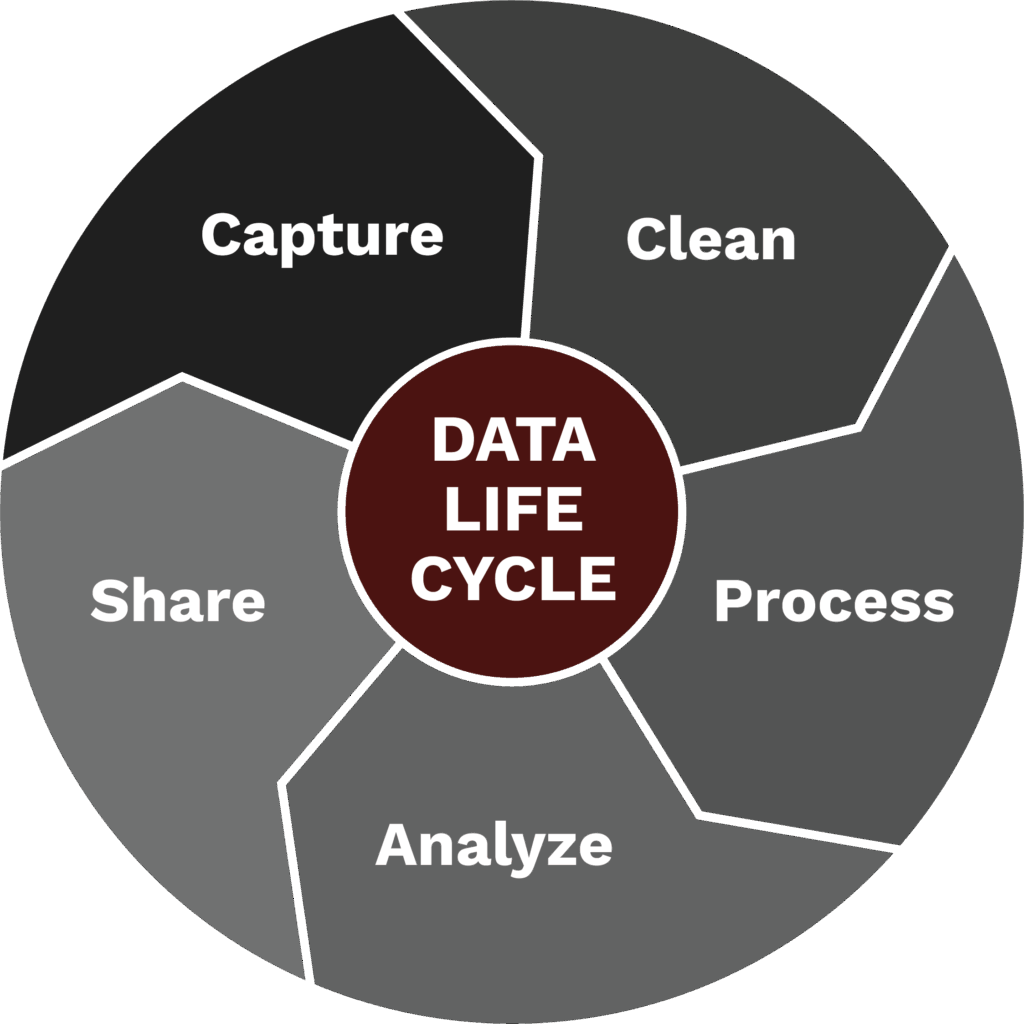
Good data preparation underpins the accuracy and reliability of all subsequent analysis, and, as a result, organizations increasingly employ specialized data engineers to support this critical phase.
Texas A&M offers several opportunities to advance your education in data science and other related fields.
From Big to Smart, Evolving Roles of Data
Data science extends beyond the volume of data (“big data”), centering on the creation of data products: applications whose value derives from data and that generate further data through use.

Google’s PageRank Algorithm
Leveraging link data to enhance search relevance.

Amazon’s Recommendation Engine
Using behavioral data to drive personalized suggestions and increase engagement.

Credit Scoring Systems
Continuously updates credit scores based on new transaction data and payment histories.
Careers in Data Science
Data Scientist
Data scientists are involved in every stage of the data lifecycle, from collecting and organizing raw data to analyzing and visualizing results, and ultimately developing innovative data-driven products. Consequently, they use a wide range of analytical tools and techniques to extract meaningful insights from data.
Data Engineer
Data engineering involves acquiring, cleaning, and structuring data so that it is ready for analysis. Data engineers build and manage the pipelines and infrastructure that underpin data science projects, ensuring that data is accessible, reliable, and well-organized.
AI Engineer
AI Engineers work collaboratively with data scientists and software developers to create intelligent algorithms and models, integrating them into robust applications and platforms. They are responsible for training and evaluating models, optimizing algorithms for performance, therefore ensuring that AI solutions align with ethical standards and business objectives.
Career Opportunities in Data Science
Data scientists have become valuable assets in almost every field and discipline.
$56-$58
Median Hourly Salary
24%
Job postings require a Master’s degree or higher
34%
Projected job market growth from 2024 to 2034
$112,590
Median annual salary
as of May 2024
11.5 million
Jobs created for data science
by 2026
Texas A&M: Leading Data Science Innovation
Texas A&M University is at the forefront of innovation in data science, engineering, and computer science, and TAMIDS is proud to be a part of the vast network of collaborative departments, labs, and other institutes that drive these fields forward. With several opportunities for educational and professional development, TAMIDS looks forward to seeing how you get involved in Texas A&M’s data science community!